
2025-06-29
Virtual Avatar Modelling & Animation in AR

The popularity of today's social media and virtual social platforms, as well as the rapid development of augmented reality and virtual reality technologies, have made personalized 3D avatar models an important way for users to express themselves and engage in virtual social interactions, such as Microsoft's release of animated models that can be created based on user photos.
The background of the development of virtual human online generation technology can be traced back to advances in the fields of computer graphics, artificial intelligence and virtual reality: Computer graphics: Computer graphics is a discipline that studies how computers are used to generate, process and display images. With the rapid development of computer hardware and software, graphics technology has made great strides in the fields of gaming, animation, film and television production.
Among them, the modeling and rendering of virtual characters is an important research direction in the field of graphics. Artificial Intelligence: the rapid development of artificial intelligence technology provides strong support for online generation of virtual characters. AI techniques such as deep learning and generative adversarial networks (GANs) enable computers to learn from large amounts of data and generate realistic avatars. By analyzing and modeling data from real-world characters, these techniques can generate avatars with realistic appearance and behavioral characteristics.
Virtual Reality: Virtual reality technology is a computer-generated simulated environment that allows users to interact with the virtual world in real time. Virtual human online generation technology plays an important role in virtual reality applications by
generating realistic avatars that enhance the user's immersion and interactive experience in the virtual environment.
This technology has a wide range of applications in gaming, virtual socialization, virtual training and healthcare. Personalization demand: With the popularity of social media and virtual social platforms, there is a growing demand for personalized expression and participation in virtual social interactions. Virtual human online generation technology can meet the user's demand for customized and personalized avatars, enabling users to realistically display their own image and characteristics in a virtual environment.
The background of avatar online generation technology stems from advances in the fields of computer graphics, artificial intelligence and virtual reality, as well as the demand for personalized avatars. By combining advanced graphics and artificial intelligence technologies, online avatar generation technology is able to generate realistic and personalized avatars that
provide users with a richer and more immersive virtual experience.
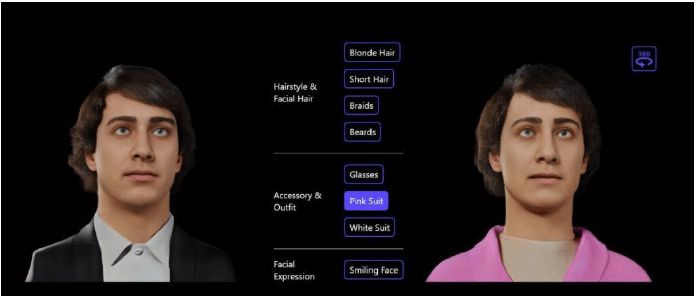
Figure1: Microsoft releases diffusion model for generating 3D avatars
1.2 Related work
Understand the significance of SMPL for human body reconstruction, get the parametric
understanding based on SMPL, so as to get the skinned effect of the human body, in order to
model better adaptability and 3D reconstruction based on photos, I need to pre-process the
dataset first, apply the photo rendering tool stable diffusion to render the photos, and the tools
in the motion wonder3D, Cross- domain diffusion model and Geometry-aware fusion to
realize the 3D animation reconstruction of the character, and then based on the skeleton
driving principle in easymocap to realize the driving of mesh.
1.3 Objectives
Search/generation of a parametric avatar mesh model based on/ extended from SMPL.
With capabilities of body shape / face feature reparameterization based on video capture.
3D avatar generation with geometrical feature alignment and restyling based on the
aforementioned parametric avatar mesh model;Using only a short video clip to map texture
over the avatar mesh.
1.4 Purpose
The purpose of the project is to provide a comprehensive solution for creating and
manipulating virtual avatars with realistic appearance and animations. By incorporating
advanced technologies such as parametric modeling, video-based reparameterization, texture
mapping, and real-time visualization, the project aims to deliver a seamless and immersive
user experience in the realm of virtual avatars, with potential applications in gaming, virtual
communication, and other virtual reality contexts.
2 Method
2.1 Problem statement
Our first objective is Search/generation of a parametric avatar mesh model based on/
extended from SMPL. With capabilities of body shape / face feature reparameterization based
on video capture. First of all, it is necessary to extract the key frames of the photos from the
video, and the characters in the extracted key frames are the real-life photos, but the final
realized result needs to be when the animation effect, it is necessary to realize this effect
efficiently, due to the lack of arithmetic power because of equipment reasons, the dataset
tends to be very small, it is necessary to reproduce the three-dimensional characters based on
the photos of a single one, it is necessary to generate a model of the photos of the multiple
perspectives, and it is also necessary to realize a realistic and high-quality model based on the
generative model.
2.2 Proposed methods
Pipeline
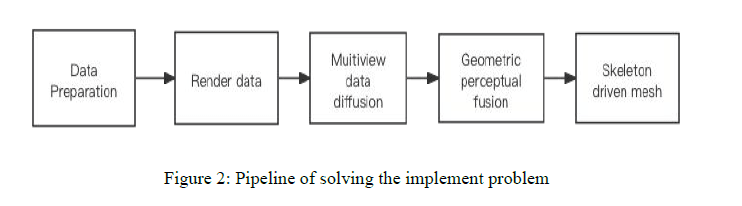
2.2.1 Data Preparation
The dataset was collected from the web, and since I relied more on diffusion models and 3D
fusion models in the method I proposed for reproducing 3D animation meshes in order to
improve the generalizability, I chose the full-body red carpet photos of three European and
American celebrities for this dataset, and in the preprocessing aspect, the backgrounds were
removed, and only the characters themselves were retained, and the quality of the image was
improved.

2.2.2 Stable Diffusion
Rendering the database, after rendering the images of the character frames, before training the
model.Diffusion model is a new generate model, comparing to the popular generation model
GAN. GAN consists of a generator, which is responsible for generating realistic data to "fool"
the discriminator, and a discriminator, which is responsible for determining whether a sample
is real or "made up". "The training of GAN is actually the two models learning from each
other.
A generative model is essentially a set of probability distributions. As shown in the figure
below, the left side is a training dataset in which all the data are random samples taken
independently and identically distributed from some data. On the right is its generative model
(probability distribution), in which a distribution Pe is found such that it is closest to Pdata.
Then pick new samples on, you can get a steady stream of new data.
Diffusion model is From a probability distribution point of view, consider the
two-dimensional joint probability distribution P(X, v) in the shape of the Swiss volume in the
figure below. The diffusion process q is very intuitive, where the sample points, which are
originally centrally ordered, are perturbed by the noise, diffuse outward, and ultimately turn
into a completely disordered noise distribution. The diffusion model is actually the inverse of
this process P, a noise distribution N (0,1) gradually denoised to map to Pdata, with such a
mapping, we sample from the noise distribution, and ultimately we can get a desired image,
that is, you can do the generation. And from a single image sample to look at this process, the
diffusion process q is to keep adding noise to the image until the image becomes a pure noise,
and the inverse diffusion process P is the process of generating an image from pure noise.
Comparing to GAN, in general, GAN generates a model that is a black box that is hard to
debug, whereas diffusion is very scalable, and on top of that, diffusion is more efficient than
GAN.
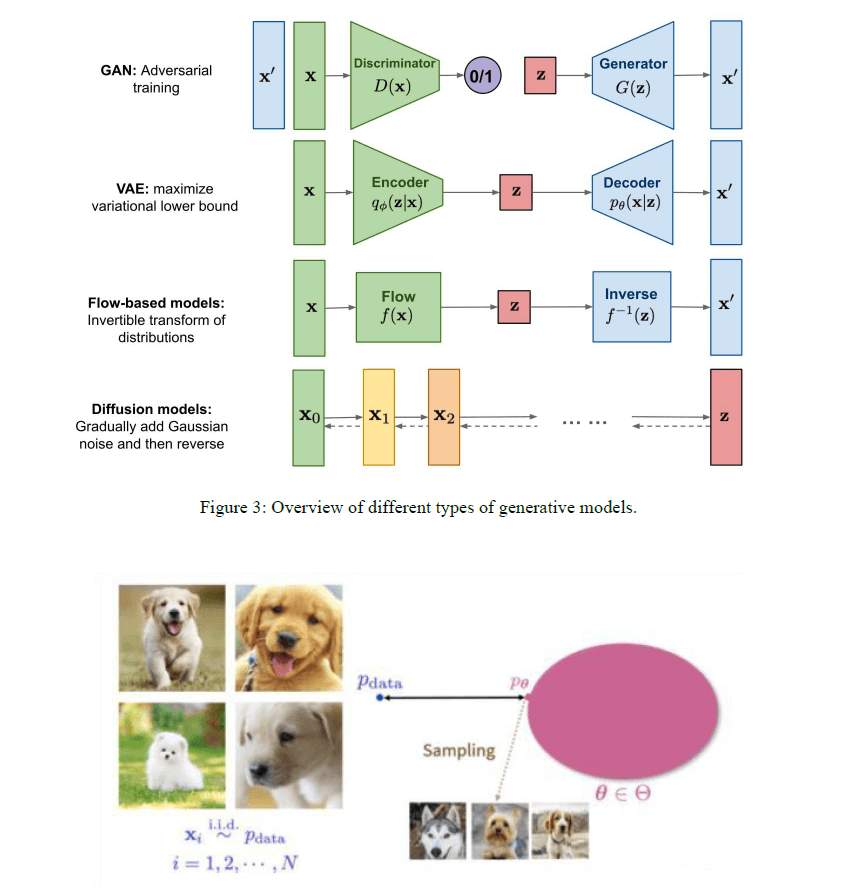
Figure 4: Generative logic for diffusion modeling
2.2.3 Cross-domain diffusion model
Based on introduction of diffusion model above, we know that diffusion model is a good
generation model. Unlike the previous diffusion model which only outputs color image,
Wonder3D can output both normal map and color image, and to achieve this goal, the authors
propose a cross-domain switcher to control whether the diffusion model produces color image
or normal map. To achieve this goal, the authors propose a cross-domain switcher to control
whether the diffusion model produces a color image or a normal map, and in order to maintain
a good consistency constraint between the normal map and the color image under the same
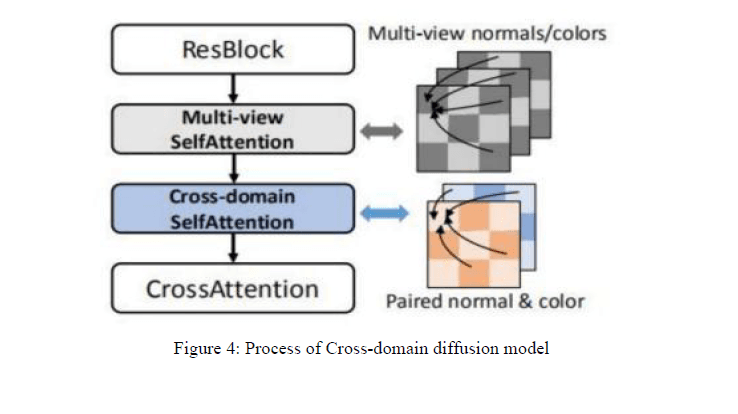
viewpoint, the authors utilize a cross domain attentions mechanism.
First, a domain switching layer is used to switch out two different layers of domains to
generate a normal and a colorful, both of which are photographs of six viewpoints, and in
order to ensure the consistency of these two domains, a cross domain attentions layer is
invoked, where the keys and values of the normal image domain and the color image domain
are combined and processed by attentional operations. This design ensures that the generation
of color images and normal maps are closely related, thus promoting geometric consistency
between the two domains.
2.2.4 Geometry-aware fusion
The use of existing sdf-based reconstruction methods, such as NeuS, proved to be infeasible.
These methods are tailored for real captured images and require dense input views.
In contrast,we generate views they are relatively sparse, and the resulting normal maps and color images
may exhibit subtle inaccuracies in the prediction of certain pixels. Wonder3D proposes
geometric fusion algorithms, the principle behind which uses normals, a configuration that
ensures that the angle between the normal vector and the observation ray remains no less than
90◦ . Deviation from these criteria will mean that the generated normals are inaccurate. In this
way, constraints are applied to the generated model. Evaluation results: Wonder3D
outperforms previous work in terms of reconstruction results, robust generalization
capabilities, and significant efficiency.
2.2.5 Skinned Multi-Person Linear Model
SMPL refers to the parametric 3D model of the human body constructed in the article "SMPL:
Skinned Multiple Person Linear Model" in 2015. The human body can be understood as the
sum of the base model and the deformations performed on top of the model to obtain the
shape parameters by PCA, which are the low-dimensional parameters characterizing the shape.
On the basis of the deformation, the shape parameters are obtained through PCA, which are
the low-dimensional parameters characterizing the shape; at the same time, the pose of the
human body is represented by the kinematic tree, i.e., the rotational relationship between each
joint and the parent node in the kinematic tree, which can be represented by a 3D vector, and
ultimately, the local rotation vectors of each joint constitute the pose of the smpl model.
Parameter (pose).
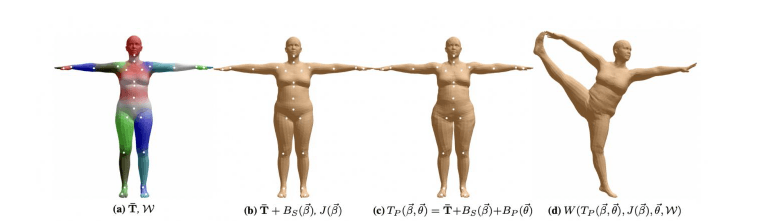
Figure 5: SMPL model. (a) Template mesh with blend weights indicated by color and joints
shown in white. (b) With identity-driven blendshape contribution only; vertex and joint
locations are linear in shape vector B. (c) With the addition of of pose blend shapes in
preparation for the split pose; note the expansion of the hips. (d) Deformed vertices reposed
by dual quaternion skinning for the split pose.
2.2.6 Skeleton Drive Grid
Because of the large variability of different human body shapes, we still need to estimate the
bone points that conform to the mesh after the two hybrid modeling methods mentioned
before, so that we can rotate these bone points to form our final desired pose. Therefore, bone
point position estimation here refers to estimating the ideal position of the bone points as
control points for the silent pose based on the position of the endpoints of the mesh in the
silent pose after hybrid molding. The whole process is solved by Eq.1
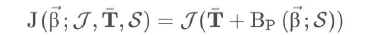
Eq1: Mesh transformation matrix
The whole process can be visualized as shown in Fig 6, where the position of each skeletal
point is determined by weighting the endpoints of a number of meshes closest to itself.
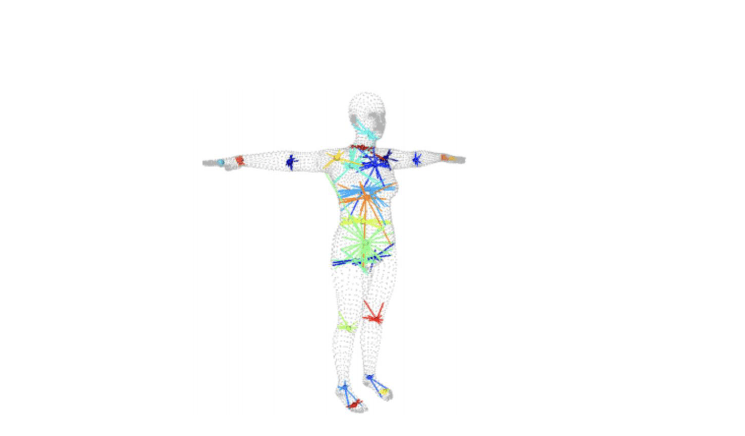
Figure 6: The endpoints of the mesh are used to estimate the spatial location of the skeletal
points that are the operating points
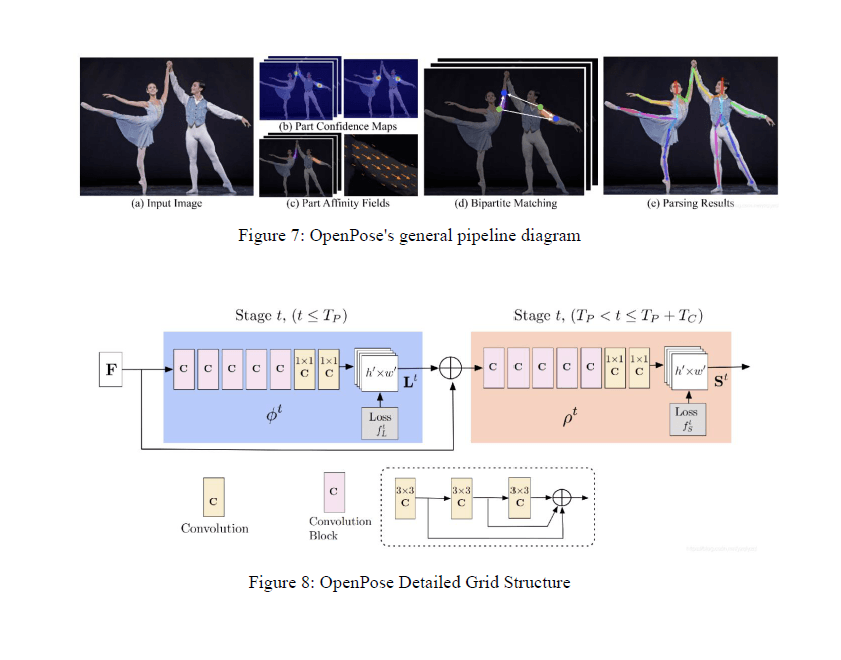
Easymocap is an open source platform based on smpl, in which openpose is used to predict
skeletal keypoints to enable skeleton-driven mesh, according to Image 7, (a) The method
takes the whole image as input to the CNN to jointly predict (b) a confidence map for body
part detection and (c) a PAF for part association.(d) The parsing step performs a set of
bipartite matches on the associated of body part candidates by performing a set of two-part
matches. (e) They are finally assembled into a complete pose for everyone in the image.
Skeleton Drive Grid.
Results
3.1 System settings
Three full-body photographs of people are used as the input dataset. These photos can contain
different people and need to cover both full body and facial features. Render using the
Stabilized Diffusion Model, a powerful text-to-image generation model that produces
high-quality images based on text descriptions. My rendering description is "Render as an
animation, preserving the character's body and facial features". This description will direct
Stabilized Diffusion to generate an animated image, but still retain the original character
features. To further improve the rendering, use ControlNet, a model that can be integrated
with Stabilized Diffusion to guide and constrain the Stabilized Diffusion generation process
using information such as edges, depth, segmentation, and more from the input image.
ControlNet will be used to extract edge, segmentation, and other information from the input
three person photos and pass this information as additional input to the stabilization diffusion
model. This will help the Stabilized Diffusion model better preserve the body and facial
features of the original characters when creating animated images. First, three photos of the
character are fed into the ControlNet model to extract edges, segmentation and other
information. Then, these ControlNet outputs are fed into the Stabilized Diffusion Model along
with the text description "Rendered for animation, preserving the character's body and facial
features." The Stabilized Diffusion Model will use the information provided by ControlNet to
produce an image that retains the original character features but in an animated style. The
final result is three rendered images.

3D mesh reproduction, using a single image as input, outputs multiple corresponding normal
maps and color images through a cross-domain diffusion model, and then uses geometric
reconstruction methods to recover texture and geometry from the normal maps and color
images. The technique route show as Figure11.
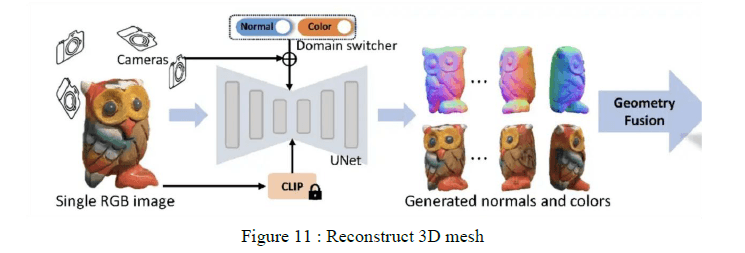
Running the above rendered dataset into Cross-domain diffusion model will generate
6-angle photos by generative model and categorized into two types of viewpoint photos:
normal and color.

3.2 Presentation and interpretation of results
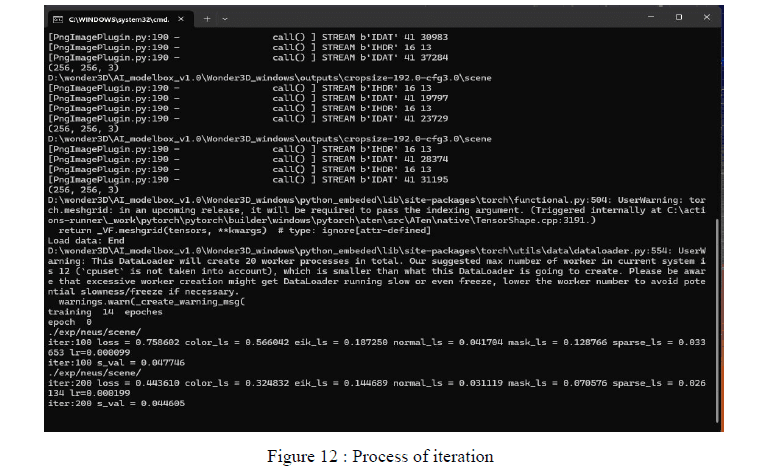
The model employs a geometric information-based normal fusion algorithm to extract
high-quality 3D surfaces from 2D representations of multiple viewpoints. This normal
fusion algorithm is an iterative optimization process, and the number of iterations can be
selected. Specifically, the algorithm first extracts normal maps from the input multi-view 2D
images, and then fuses these normal maps to a uniform 3D surface through an iterative
optimization process. In each iteration, the algorithm updates the normals and vertex
positions of the 3D surface based on the current 3D surface and the input normal maps to
minimize the differences between the normal maps and the 3D surface. The number of
iterations is a hyper-parameter that can be set, usually between 10 and 50 attempts are made.
The higher the number of iterations, the higher the quality of the fused 3D surface, but with
a corresponding increase in computation time. Through this iterative optimization process
based on geometric information, Wonder3D is able to generate high-fidelity 3D textured
mesh models from a single input image, and the number of iterations can be adjusted
according to the demand to balance quality and efficiency. The iterative process is shown in
Figure 13.
Finally, a more efficient reproduction is obtained by driving the mesh model through the
skeleton.

4 Discussion
4.1 Reproducibility of methods, code, data, and results
The purpose of this report is to provide an overview of the reproducibility of methods, code,
data, and results for modeling and animating the appearance of virtualized bodies in an
augmented reality (AR) environment. The focus of the report is on the environment in which
the models are run, which includes various dependencies such as Torch, torchvision, diffusers,
xformers, transformers, and so on. Among them the image rendering model: stable diffusion,
the 3D fusion model: geometry-aware fusion, and the Mesh skeleton driven model are trained
reproducibly. The report provides a detailed list of code and dependencies required to run the
virtualized body appearance modeling and animation models. These dependencies include
Torch (1.13.1), torchvision (0.14.1), diffusers[torch] (0.19.3), xformers (0.0.16), transformers
(>=4.25.1), bitsandbytes (0.35.4), decord (0.6.0), pytorch-lightning (<2), omegaconf (2.2.3),
nerfacc (0.3.3), trimesh (3. 9.8), pyhocon (0.3.57), icecream (2.1.0), PyMCubes (0.1.2) ,
accelerate, modelcards, einops, ftfy, piq, matplotlib, opencv-python, imageio, imageio-ffmpeg,
scipy, pyransac3d, torch_efficient_distloss, tensorboard, rembg, rembg, rembg, rembg, rembg,
rembg, rembg, rembg, rembg. tensorboard, rembg, segment_anything, and gradio (3.50.2).
For data processing, a background-free, clear full-body photo of the person is required, and
the preprocessing needs to fulfill the png format.
4.2 Difficulties and limitations
In order to retain better results, I used 10,000 iterations. Although wonder3D implements the
algorithm to reproduce with only one photo, the time to run 10,000 iterations is still very long,
and there are hard requirements on the machine's arithmetic and storage, so the adaptability of
this model is a bit poorer. In addition to that, due to the rendering effect of STABLE
Diffusion, the rendered In addition, due to the rendering effect of stable diffusion, the
rendered photos are often very different from the real-life photos, and many of wonder3D's
strengths lie in the re-realization of real-life type of photos, and for the overly abstract
rendered animated photos, the reproduction of the facial details will be a little bit worse.
4.3 Potential improvement and future work
Further improvement of geometry-awareness: Wonder3D has proposed a geometry-aware
normal fusion algorithm to extract high-quality 3D surfaces from multi-view 2D
representations. In the future, we can continue to explore more accurate geometry-aware
methods, such as utilizing Voronoi diagrams to describe local geometric structures,
introducing edge domain adaptive stereo matching algorithms, etc., to further improve the
geometric accuracy of 3D reconstruction.
Enhancing cross-modal consistency: Wonder3D adopts a multi-view cross-domain attention
mechanism to facilitate information exchange between different views and modalities (normal
map, color map). In the future, it can be further investigated how to enhance the cross-modal
consistency to ensure that the generated 3D geometries and textures are more harmonized.
Improve computational efficiency: Wonder3D has been able to generate high-quality 3D
texture mesh from a single image more efficiently than previous methods. In the future, the
algorithm can be optimized to further improve the computational efficiency and make it more
practical for real-world applications.
Expanding to more complex scenes: Currently, Wonder3D mainly focuses on 3D
reconstruction of single objects, but in the future, we can explore how to expand it to more
complex scenes, such as indoor scenes, urban scenes, etc., in order to satisfy a wider range of
application needs.
Combining with multi-sensor fusion: We can consider combining Wonder3D with ADAS
multi-sensor fusion technology to improve the accuracy and robustness of 3D reconstruction
by utilizing multi-sensor data.
5 Conclusion
So far, for the reconstruction of 3D character models, people have made and realized a lot of
progress, from SMPL to easymocap to stable diffusion, and finally wonder3D, this is my step
by step realization of animation character reproduction step by step, the algorithms behind
each model contain this era for the advancement of the understanding of artificial intelligence,
animation model reproduction is not a simple thing, in our current era, the most mainstream
animation modeling, is the animation modeler modified little by little, which makes me
believe that the real realization of real-time human animation model reproduction is not a
simple thing. The reproduction of animation models is not a simple thing, in our current era,
the most mainstream animation modeling, is the animation modeler bit by bit to modify out,
just rely on the computer to let this process to achieve this is undoubtedly very exciting, based
on the results I have achieved, the effect of the reproduction of the human body is insufficient,
which there are still a lot of places that can be improved, I hope that through my future
learning, I can realize the progress! I also believe that in the near future, human beings will be
able to realize real-time camera-based human animation model reproduction.



EDPS Systems Limited EDPS 電腦系統有限公司 EA Licence No. 78592
© Copyright of EDPS Systems Limited 2026. All Rights Reserved.