
2025-05-31
Image Re-Colorization for Art & Design

In the realm of art and design, the color of images holds great significance. Its purposefulness is multi-faceted, being paramount for attracting viewers and users in a variety of applications such as flat media, advertisements, and wallpapers. Often, the colors need to be deliberately changed to align with specific design themes or to achieve targeted visual goals. This project introduces a novel multi-modal image re-coloring pipeline, dynamically adjusting colors in images based on natural text, precise user clicks or reference images. By using Vision Transformers, semantic hints are effectively propagated across image and Sub-Pixel Convolution is utilized for real-time inference. The project aims to bring improvement in existing field of image re-colorization while giving end-users a semiautomated process of image re-colorization without specific needs for domain knowledge.
Keywords — Interactive Colorization, Vision Transformer,
Computational Photography, Image Manipulation, Neural
Networks
I. INTRODUCTION
This project introduces a multi-modal interactive colorization pipeline with real time inference. Its key contributions are:
- Multi-modal (text, clicks and exemplar image) conditional image colorization using hint points as intermediate representation.
- Vision Transformer with Sub-Pixel convolution achieving real time inference without requiring extensive computational resources.
II. METHODOLOGY
- A. User Hint Generation
In the first step, our model converts different types of user input to hint point masks which acts as an input alongside the image for colorization operation. The model supports three types of input. For textual input, we use a special pipeline utilizing CLIP [1] to convert to hint points. For reference image, we use warping and deep learning based [2] operation to generate hint points. Lastly, users can also manually select their preferred points and desired color through precise clicks and color selection through color gamut.
- B. Colorization Operation
As seen in Figure 1, Once Hint points are generated, patches of input image are created which is encoded in a positional layer and passed into a Vision Transformer [3] backbone.
This backbone effectively propagates the user hint points respecting semantic context. Once the features are generated the image is up sampled using a sub-pixel convolution
technique, which reshapes channel dimension to increase
spatial resolution. However, for larger ratio, artefacts can be produced. Because of this, an additional Stabilizing layer (which is a modified Convolutional Neural Network) isadded to group and scale neighboring pixels to achieve
smoother upscaling. This allows our model to achieve real time inference without requiring extensive computational resources.
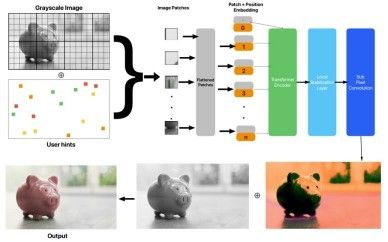
Fig. 1. The model takes as input an image and user hint (generated through text, reference image or precise clicks), and passes it into a vision transformer encoder and performs stabilized sub-pixel convolution to generate precise color with rich semantic understanding.
III. METHODOLOGY
TABLE I : INFERENCE SPEED OF CAPSTONE MODEL AGAINST OTHER BASE LINE MODELS.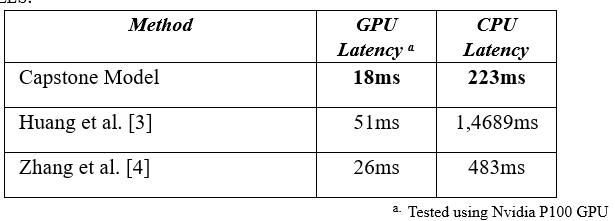
Table 1 highlights, Capstone model’s efficient inference, particularly enabled by its sub-pixel convolution, which is significantly faster than traditional decoder based models.
IV. CONCLUSION
In conclusion, our interactive multi-modal image recolorization pipeline marks a good advancement in art and
design applications, blending user input with cutting-edge AI to deliver real-time, semantically aware colorization. REFERENCES
- A. Radford et al., “Learning Transferable Visual Models From Natural Language Supervision,” CVPR, pp. 8748–8763, Jul. 2021.
- B. Zhang et al., “Deep Exemplar-Based Video Colorization,” Conference on Computer Vision and Pattern Recognition, Jun. 2019, doi: 10.1109/cvpr.2019.00824.
- Z. Huang, N. Zhao, and J. Liao, “UniColor: A Unified Framework for
Multi-Modal Colorization with Transformer,” arXiv (Cornell University), Jan. 2022, doi: 10.48550/arxiv.2209.11223. 



EDPS Systems Limited EDPS 電腦系統有限公司 EA Licence No. 78592
© Copyright of EDPS Systems Limited 2026. All Rights Reserved.